القاهرة-
أطلقت شركة علي بابا الصينية 4 نماذج متطورة في مجال الذكاء الاصطناعي، في خطوة تستهدف قيادة المنافسة العالمية في تقنيات الفهم والتوليد متعدد الوسائط.
وقالت الشركة، في بيان، إن النماذج الجديدة تركز بشكل رئيسي على تقديم إمكانيات متطورة للمستخدمين والمطورين لإتاحة تجارب أكثر تنوعاً، وتفتح الباب أمام تطوير نماذج مخصصة لاستخدامات معينة، موضحة أن مصادر النماذج الجديدة مفتوحة ما يسمح بتطويرها وتعديل أكوادها.
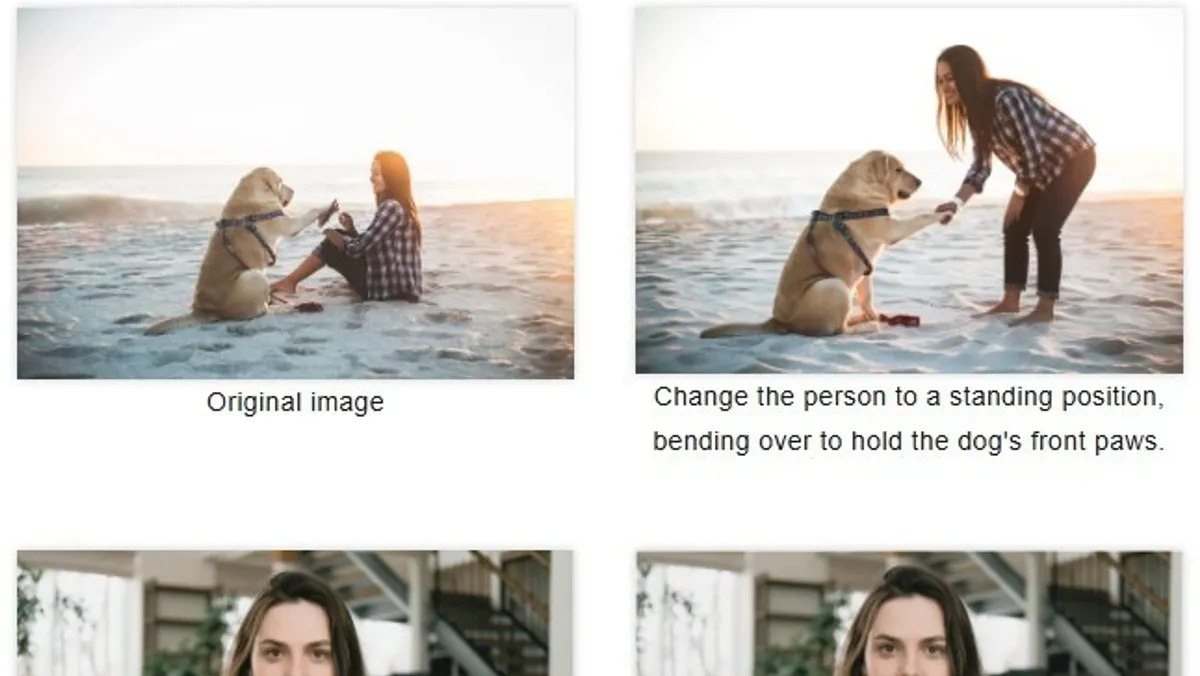
Wan 2.5 يحول النصوص والصور إلى فيديو
النموذج الأول هو Wan 2.5 لإنتاج الفيديوهات والذي يسمح بإنتاج مقاطع قصيرة مدتها تصل إلى 10 ثوانٍ وبجودة 1080p مع تزامن تلقائي بين الصوت والصورة، ما يتيح إنشاء مقاطع مرئية متكاملة دون حاجة لتدخل بشري يدوي في المزامنة.
ويُمكن للمستخدمين إدخال النصوص أو الصور، بل وأحيانًا ملفات صوت مخصصة، ليولّد النظام تلقائيًا المقطع المرئي المناسب، مع تشغيل صوتي متزامن يشمل الغناء أو المؤثرات أو الموسيقى الخلفية.
وتمنح هذه المرونة في التعامل مع مدخلات متعددة الوسائط، المستخدمين إمكانيات إبداعية واسعة.
ووفرت الشركة مزايا تحرير الصور داخل النظام نفسه، حتى يتمكن المستخدم تعديل التفاصيل بدقة، مثل دمج مفاهيم متعددة، تحويل المواد الخام، أو تبديل ألوان المنتجات، مما يجعل النموذج أداة متكاملة للإبداع البصري.
Qwen3‑Omni.. الذكاء الاصطناعي متعدد الوسائط بالكامل
بالتزامن مع إطلاق Wan 2.5، كشفت علي بابا عن نموذج ذكي جديد ضمن عائلة Qwen، أطلقت عليه اسم Qwen3‑Omni، والذي يُصنَّف باعتباره أول نموذج في عائلة نماذج علي بابا قادر على دعم متعدد الوسائط واستيعاب وتوليد نصوص وبيانات بصرية وصوتية وفيديو ضمن بنية واحدة.
ويدمج Qwen3‑Omni في تصميمه مكوّنين رئيسيين هما Thinker و Talker، إذ يُعنى Thinker بمعالجة وفهم المدخلات متعددة الوسائط، بينما يتولى Talker إنتاج الكلام الصوتي المتزامن في الزمن الحقيقي.
ويستخدم النموذج أسلوب Mixture-of‑Experts لتقسيم العمل بين اختصاصيين داخليين لتقديم أداء عالي في عدة مهام دون تداخل أو تراجع في جودة الأداء.
ومن الناحية اللغوية، يدعم Qwen3‑Omni التعامل مع 119 لغة للنصوص، و19 لغة لمعالجة الصوت، و10 لغات لإنتاج الكلام، كما يستطيع استقبال مدخلات صوتية تصل إلى 30 دقيقة، ويقدّم استجابة أولية first‑packet latency تصل إلى نحو 234 مللي ثانية للصوت و547 مللي ثانية للفيديو، ما يجعله مناسبًا لنظام الدردشة الصوتية والمرئية في الزمن الفعلي.
إصدارات Qwen3‑Omni المخصَّصة
أطلقت علي بابا 3 إصدارات من Qwen3‑Omni، كل منها يلبي احتياجات متخصصة. النسخة Instruct هي الأكثر تكاملاً إذ تستقبل مدخلات نصية وصوتية وبصرية وتنتج مخرجات نصية وصوتية.
النسخة الثانية هي Thinking تركز على مهام التحليل والتفكير العميق، وتستقبل نفس المدخلات لكنها تكتفي بالإنتاج النصي فقط، ما يجعلها مثالية للتطبيقات التي تحتاج إلى إجابات مكتوبة معقدة.
النسخة الثالثة Captioner مختصة بتوليد وصف صوتي دقيق ومنخفض التحيز لأي مدخل صوتي، وتُستخدم في تطبيقات مثل الترجمة الصوتية أو وصف المحتوى الصوتي للمكفوفين.
وحقق Qwen3‑Omni أداءً متفوقًا في اختبارات معيارية متعددة، إذ تفوَّق على النماذج المفتوحة في 32 من أصل 36 معياراً، بينما تصدر في 22 معيارًا عالميًا، متجاوزًا نماذج منافسة مثل Gemini 2.5 وGPT‑4o في بعض الاستخدامات متعددة الوسائط.
وطرحت علي بابا Qwen3‑Omni تحت رخصة Apache 2.0 للبرمجيات مفتوحة المصدر، ما يتيح للمطورين والمؤسسات استخدامه وتعديله ودمجه في التطبيقات التجارية بحرية، مع تقديمه عبر منصات مثل GitHub وHugging Face وModelScope.
وتُعد عائلة Qwen من النماذج التي أطلقتها علي بابا منذ عام 2023، وتتضمن إصدارات متخصصة لنماذج اللغة البحتة Qwen، Qwen2، Qwen3 بالإضافة إلى نماذج متخصصة في الصور والصوت Qwen‑VL، Qwen2.5‑Omni وغيرها.
Qwen3 Max.. الإصدار الأقوى على الإطلاق
كشفت الشركة الصينية عن نموذجها الجديد Qwen3‑Max، الذي وصفته بأنه الأضخم في تاريخها، ويُعد تتويجًا لسلسلة نماذج Qwen التي طورتها الشركة منذ عام 2023.
يأتي هذا النموذج بتصميم معماري ضخم يتجاوز التريليون معامل، ليشكّل تحديًا صريحًا لنماذج الشركات الأميركية الرائدة في هذا المجال، مثل GPT-4 من OpenAI وجيميناي من جوجل.

Qwen3‑Max هو نموذج لغوي ضخم متعدد الأغراض، جرى تدريبه باستخدام كمية هائلة من البيانات النصية من مصادر متنوعة، ويعمل في وضعيتي Instruct وThinking، الوضع الأول مخصص لتقديم إجابات تفاعلية مباشرة بناءً على الأوامر والتعليمات، فيما يُستخدم الوضع الثاني لتحليل السياقات العميقة وسلاسل التفكير المنطقية الممتدة.
ويستند النموذج إلى بنية متقدمة من نوع Mixture-of-Experts، تتيح له معالجة كميات ضخمة من البيانات بكفاءة عالية، مع الحفاظ على اتساق الإجابات في مختلف اللغات والمجالات التخصصية.
وحقق Qwen3‑Max نتائج متقدمة في اختبارات الأداء المعيارية، بحصوله على 69.6 نقطة في اختبار SWE‑Bench الخاص بتحليل مشكلات البرمجيات وإيجاد حلولها، ما يجعله من أفضل النماذج أداءً في هذا النوع من المهام التقنية.
وأظهر النموذج قوة ملحوظة في اختبارات المحادثة طويلة المدى والقدرة على فهم النوايا والسياقات المتشابكة، خصوصًا في اختبار Tau2‑Bench الذي يقيس قدرات النماذج في بناء وكلاء ذكيين للتفاعل مع المستخدم.
وعلى غرار النماذج الأخرى في عائلة Qwen، أطلقت الشركة نموذج Qwen3‑Max ضمن مشروع مفتوح المصدر، ما يتيح للمطورين والباحثين والمؤسسات استخدام النموذج بحرية تامة، وتخصيصه لاحتياجاتهم، سواء في القطاعات التجارية أو الأكاديمية أو الحكومية.
ومن المتوقع أن يلعب النموذج دورًا كبيرًا في التطبيقات المستقبلية التي تتطلب فهمًا عميقًا للغات الطبيعية، بما في ذلك منصات الدعم الفني، نظم تحليل البيانات، والأنظمة التفاعلية في القطاعات الصحية والتعليمية.
يأتي إطلاق Qwen3‑Max ضمن خطة استراتيجية شاملة أعلنت عنها علي بابا، تتضمن استثمارًا بقيمة 380 مليار يوان صيني (نحو 53 مليار دولار) لتوسيع البنية التحتية للذكاء الاصطناعي والحوسبة السحابية خلال السنوات الثلاث المقبلة.
تصنيفات








