القاهرة-
أعلنت جوجل إطلاق نموذجها الجديد Gemini Omni، في خطوة توسّع قدرات الذكاء الاصطناعي التوليدي داخل منظومة Gemini، عبر تقديم نموذج قادر على إنشاء مقاطع فيديو وتحريرها اعتماداً على مدخلات متعددة، تشمل النصوص والصور والصوت.
وقالت الشركة إن النموذج الجديد يمثل نقلة جديدة في تطوير النماذج متعددة الوسائط، إذ يجمع بين قدرات الاستدلال والفهم السياقي التي تتميز بها نماذج جيميناي، وبين إمكانيات إنتاج المحتوى الإبداعي بصورة تفاعلية.
وأضافت أن النموذج صُمم ليتيح للمستخدمين إنشاء محتوى مرئي متكامل انطلاقاً من أي مدخلات تقريباً، مع تركيز خاص على إنتاج الفيديو.
كيف يعمل Gemini Omni؟
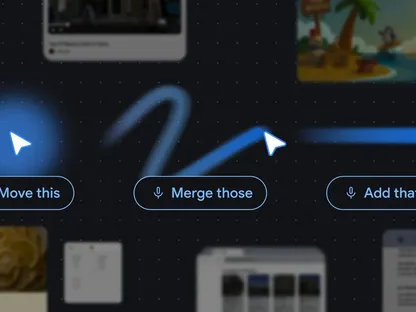
وبحسب جوجل، فإن Gemini Omni يتيح للمستخدمين تعديل الفيديوهات من خلال المحادثة فقط، عبر أوامر مكتوبة باللغة الطبيعية، بحيث تتحول عملية المونتاج التقليدية إلى تجربة تفاعلية تعتمد على التعليمات النصية المباشرة.
وأكدت الشركة أن النموذج يحافظ على اتساق الشخصيات والعناصر البصرية داخل المشاهد، حتى مع إجراء تعديلات متتالية على الفيديو.
وأشارت إلى أن المستخدم يستطيع تغيير البيئة المحيطة بالكامل أو تعديل عناصر محددة داخل المشهد، كما يمكنه إعادة تخيل الأحداث داخل الفيديو عبر إضافة شخصيات جديدة أو تغيير الحركة أو تحويل المشهد إلى سيناريو مختلف تماماً.
وأضافت أن Gemini Omni قادر أيضاً على تنفيذ تعديلات متعددة عبر جلسات متتابعة، مع الحفاظ على الترابط السردي والبصري للمشهد الأصلي.
وأكدت جوجل أن Gemini Omni لا يقتصر على إنتاج مشاهد تبدو واقعية بصرياً، بل يعتمد أيضاً على فهم أعمق للسياق وما يجب أن يحدث داخل المشهد.
وذكرت أن النموذج يجمع بين فهم العوامل الفيزيائية وبين قاعدة معرفة جيميناي في مجالات مثل التاريخ والعلوم والثقافة، ما يساعد على إنتاج فيديوهات أكثر اتساقاً وواقعية.
وأضافت الشركة أن النموذج يتمتع بفهم محسّن لعناصر مثل الجاذبية والطاقة الحركية وديناميكيات السوائل، وهو ما ينعكس على جودة الحركة والتفاعل داخل الفيديوهات المُنشأة بالذكاء الاصطناعي.
كما أشارت إلى أن Gemini Omni قادر على الربط بين اللغة والصور والمعاني بطريقة تتجاوز أساليب مطابقة الأنماط التقليدية، بما يسمح بإنتاج محتوى بصري أكثر ترابطاً من الناحية السردية.
تنوع المدخلات
ومن بين أبرز المزايا التي كشفت عنها جوجل قدرة Gemini Omni على إنشاء فيديوهات اعتماداً على أي نوع تقريباً من المدخلات، سواء كانت صوراً ثابتة أو نصوصاً أو رسومات أو ملفات صوتية أو مقاطع فيديو مرجعية.
وأوضحت الشركة أن النموذج يستطيع دمج هذه العناصر داخل مشهد موحد ومتناسق بصرياً، مع دعم تطبيق الأنماط البصرية والمؤثرات والحركات المختلفة باستخدام أوامر نصية مباشرة.
كما أعلنت الشركة تطوير ميزة جديدة تحمل اسم Avatars، تتيح للمستخدمين إنشاء شخصيات رقمية تحاكي أصواتهم لاستخدامها في إنتاج الفيديوهات.
مخاوف التضليل
وقالت "جوجل إنها تعمل على تطوير هذه الميزة بصورة مسؤولة، مع وضع ضوابط واضحة للحد من إساءة الاستخدام، موضحة أن التقنية ستتيح مستقبلاً إنشاء نسخة رقمية من المستخدم يمكنها الظهور داخل الفيديوهات وكأنها شخصية حقيقية.
وفي إطار جهود مكافحة التضليل والمحتوى الزائف، أكدت جوجل أن جميع الفيديوهات التي يتم إنشاؤها باستخدام Gemini Omni ستتضمن تقنية SynthID، وهي علامة مائية رقمية غير مرئية تساعد على التحقق من أن المحتوى تم إنشاؤه أو تعديله بواسطة الذكاء الاصطناعي.
وأضافت أن أدوات التحقق ستتوفر عبر تطبيق Gemini ومتصفح Chrome ومحرك بحث جوجل، إلى جانب أدوات إضافية لشرح كيفية إنشاء المحتوى وتحريره.
وبدأت جوجل طرح أول نموذج ضمن عائلة Omni تحت اسم Gemini Omni Flash، إذ أصبح متاحاً لمشتركي خطط Google AI Plus وGoogle AI Pro وGoogle AI Ultra عبر تطبيق جيميناي ومنصة Google Flow وYouTube Shorts، على أن يصل أيضاً إلى مستخدمي YouTube Create خلال الفترة المقبلة.
ويأتي إطلاق Gemini Omni في ظل المنافسة المتسارعة بين شركات التكنولوجيا الكبرى لتطوير أنظمة ذكاء اصطناعي قادرة على إنتاج الفيديوهات اعتماداً على الأوامر النصية، في سباق يشمل شركات مثل OpenAI وميتا وعدداً من الشركات الناشئة المتخصصة في أدوات توليد الفيديو بالذكاء الاصطناعي.
تصنيفات